IT研究中心
继往开来,创新无限
继往开来,创新无限

未来已来,现实将被彻底颠覆!

AI视频创意图由微软 Copilot 生成
马斯克再度预言成真,2024果然是人工智能电影元年——GPT 技术带来的新一轮人工智能热潮持续席卷全球一年之后,龙年伊始 Sora 再次横扫千军。

图注:2023年11月27日 Pika 爆火后,马斯克预判称明年将是“人工智能电影”元年
近日,Sora 以文字一键输出的一分钟连贯视频里,呈现出高度细致的背景、精致复杂的多角度镜头,以及富有情感的多个角色,横扫此前一切 AI 视频技术,可谓豪气干云。
根据 OpenAI 的说法,Sora 是结合了 Transformer 和 Diffusion 这2个迄今最重要的模型:ChatGPT、Gemini、LLaMA 等语言模式都是基于 Transformer 模型——对词语进行标记,并生成单词;Diffusion 模型则被归类是“文生图”的模型。
有专业机构指出,如果从“理解世界”的角度来审视 Sora,那么某一帧图像的画质、画面关系绝不是模型质量高低的评判标准,甚至官网释出的 60 秒一镜到底视频也不是最核心的部分。真正的重点在于视频存在不同机位,不论远、中、近、特、广,视频中人物和背景的关系都保持着相当的一致性。这才是业界认为 Sora 的遥遥领先之处。

图片来自网络:Sora跟其他多个视频模型的区别
Sora 如此吸睛的原因不仅在于AI如何生成视频,更在于这背后的意义——即训练 AI 理解物理世界,继而生成各种真实场景的可能性。世界对 Sora 的关注,体现的其实是人们对未来“世界模拟视频生成模型”的展望和期待。正因如此,Sora 的亮相也极大概率会促进通用人工智能(AGI)的加速到来。

视频剪辑创意图由微软Copilot生成
所谓“世界模拟器”的说法,源自 OpenAI 官网上一篇关于 Sora 的名为《把视频生成模型作为世界模拟器》的研究论文,文中 Open AI 自称Sora是“世界模拟器”。然而也有不少大神级科学家对此并不认同。比如图灵奖得主、Facebook 首席AI科学家杨立昆( Yann LeCun)就认为 Sora 不能理解物理世界,并顺势安利了 Meta 前几天推出的AI视频模型 V-JEPA 联合嵌入预测架构的优越性。
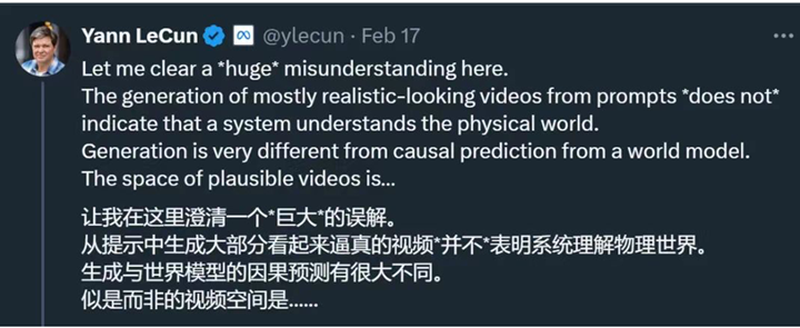
杨立昆在海外社交媒体发表见解,否认 Sora 能够理解物理世界
此外,前谷歌、Facebook 技术主管 Hongcheng 也在近期表示 AI 模型不大可能通过被动看训练数据视频,就能掌握物理定律。更有专家分析认为,从 Sora 生成的部分视频来看,它是依赖于数据插值和潜空间拼贴来生成图像,而非真实的物理模拟……各种说法纷至沓来,一时之间难分高下。

视频剪辑创意图由微软Copilot生成
回顾过去几年,大语言模型(LLM)和视频生成技术(Video GC)一直不断进步,AI 在视频创作领域的运用,不仅降低了视频创作的时间和人力成本,也为视频创作者们提供了源源不断的创意,从而极大地提升了视频内容的生产效率。
Sora 问世前,按照视频生成方式进行划分,流行的 AI 视频生成“三件套”包括文字生成视频、图片生成视频、视频生成视频。据此, Runway 、Pika、Descript 都曾成在彼时红极一时。其中 Runway 主打视频风格迁移的 Gen-1 和主打文本生成视频的 Gen-2,该技术早已被应用于电影、电视与广告等领域:去年横扫奥斯卡7项大奖的电影《瞬息全宇宙》背后的视觉效果团队就使用了 Runway 的技术来帮助创建某些场景,比如用 AI 工具去除背景、放慢视频、制作无限延伸的图片等等。

电影《瞬息全宇宙》海报
Pika 则在2023年后半程备受关注——产出质量上优于 Runway,且操作更为简单:这家仅4人的初创 AI 公司,仅六个多月内就结束测试、发布了首款正式产品 Pika1.0,生成并编辑3D动画、动漫、卡通等微电影。

图为一句话“elon musk in a space suit,3d animation”生成的视频
Descript 则和 Runway 及 Pika 有所不同,它能够将视频转录成文本,让用户通过简单修改文本来同步编辑视频。只需修改文字,视频就会随之改变。

Descript功能示意
语音克隆是 Descript 提供的另一项有趣且实用的功能——用户可以克隆自己的声音,以此编辑视频,轻松消除口误,并能调整讲话中的停顿和语气,是集写作、录音、转录、编辑、协作和分享视频与播客于一身的 AI 工具。通过 Descript,用户可以像使用文档和幻灯片一样轻松完成视频编辑,从而节省下大量时间和精力,更加专注于创意部分。
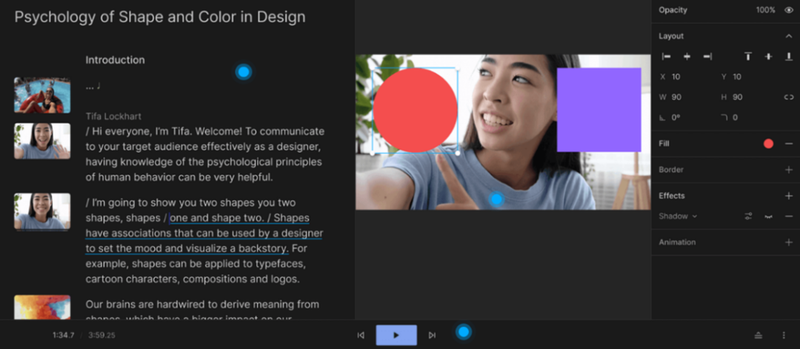
通过编辑文本来编辑视频中的图片颜色
除了上述提及的产品,过去一年中,不少公司还积极借助大语言模型(LLM)的崛起,为 AI 视频创作开拓了更多新领域。比如 ChatGPT 中的 Visla 插件可以根据用户输入的一句话,快速生成有字幕、有语音讲解、有情节的小视频。

Visla插件
HourOne 则利用字符生成技术(Character Generation Technology),通过 AI 将人类的外貌、声音和动作复制出来,创建出所谓的"虚拟人"。这些虚拟人物可以在视频中朗读文本,从而化身为“教师”“新闻播报员”“虚拟代言人” 等角色。

HourOne功能示意
Fliki 的最大亮点则在于,可以根据文本生成逼真的人类语音和视频内容,并配以相应的虚拟人物或动画创造出吸引人的视听内容。
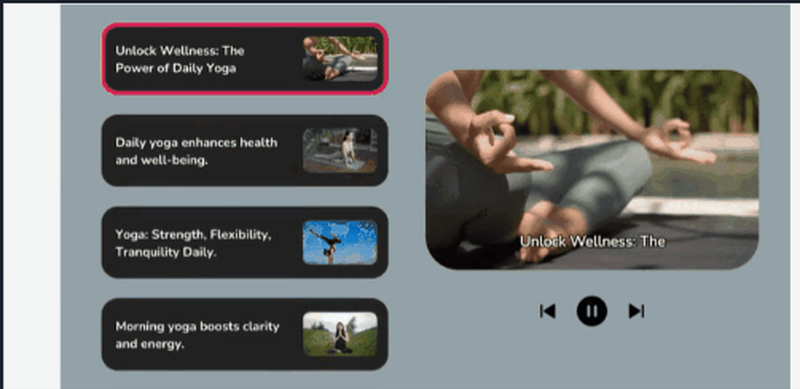
Fliki功能示意
回顾至此,不难发现短短一年,AI 视频技术的发展就实现了垂直增长:视频创作将来便捷化、智能化、高效化的时代。AI 技术不仅为创作者们带来更加丰富多样的创作方式和体验,更令视频创作不再局限于专业领域,促使普通用户轻松参与其中,创造出独具个性和创意的视频作品,为 AI 时代成为单人创业家创造了良好的先决条件。
垂直增长这一概念,由微软全球资深副总裁张祺博士于去年3月首次提出,并发起了“单人创业家(One-Person Entrepreneur)”行动,是指利用 AI 技术的能力和潜力,以“单人+ AI 即团队”的模式,实现垂直创新和垂直增长。

站在2024龙年伊始,作为这场变革的见证者和推动者,期待着视频创作领域在 AI 的引领下蓬勃发展,期待这一技术颠覆行业的时代,视频创作者们能进一步通过技术实现单人创业,开创崭新的创作纪元。
——转载自微软科技微信公众号2024年3月4日发布文章
